Journal of Information Technology & Software Engineering
Open Access
ISSN: 2165- 7866
ISSN: 2165- 7866
Review Article - (2025)Volume 15, Issue 1
Cocktail party problem is the scenario where it is difficult to separate or distinguish individual speaker form a mixed speech from several speakers. There have been several researches going on in this field but the size and complexity of model is being traded off with the accuracy and robustness of speech separation. “Monaural multi-speaker speech separation” presents a speech-separation model based on the transformer architecture and its efficient forms. The model has been trained with the LibriMix dataset containing diverse speakers’ utterances. The model separates 2 distinct speaker sources from a mixed audio input. The developed model approaches the reduction in computational complexity of the speech separation model, with minimum tradeoff with the performance of prevalent speech separation model and it has shown significant movement towards that goal. This project foresees, a rise in contribution towards the ongoing research in the field of speech separation with computational efficiency at its core.
Cocktail party problem; Complexity; Efficiency; Monaural; Speech-separation; Transformer
Monaural multi-speaker speech separation is the task of separating individual speakers from a single audio recording, which is also known as the cocktail party problem [1]. This problem is challenging because of the overlapping speech signals, the variability of speakers and environments, and the lack of spatial cues in the monaural case. However, solving this problem has many applications in various fields such as speech processing, telecommunications, entertainment, surveillance, and human-computer interaction.
In recent years, deep learning methods have achieved remarkable results in monaural speech separation, especially with the development of end-to-end models that directly estimate the source signals from the mixture signal. However, most of these models rely on large-scale and high-quality datasets, which are not always available or easy to obtain. Moreover, these models often have high computational complexity and memory requirements, which limit their practical deployment and scalability.
In this paper, we propose a novel perceiver-based architecture for monaural speech separation that aims to reduce the computational complexity and improve the performance of existing models.
The perceiver is a recently proposed model that combines self-attention and convolutional neural networks to process various types of inputs with a fixed number of parameters. We adapt the perceiver to speech separation by using a recurrent output layer and a masking-based objective function. We evaluate our model on the LibriMix dataset, which is a publicly available dataset for speech separation. We compare our model with several state-of-the-art models and show that our model achieves competitive results with much fewer parameters and faster inference time. We also analyse the effect of different hyperparameters and components on the performance of our model. We hope that our work can inspire further research on transformer-based models for speech separation and other speech processing tasks.
Early study of the speech source separation began with beamforming, a spatial filtering technique that leverages sound wave direction and phase difference to separate sources [2]. In the late 90’s and early 2000’s, single channel speech source separation was approached using statistical methods such as using eigen decomposition, ICA, including maximum likelihood approach based on EM algorithm [3-5].
The rise of machine learning has changed the way speech separation task is perceived, Hu K, et al. proposed iterative model based on GMM and DNN that could model the sources of signals and estimate the separation matrices respectively, thus intaking source’s characteristics into account for the separation task [6]. DNN based model to estimate the complex non-linear relationship between the mixed signal and targets were being proven to be exceptional in the field one after another [7,8]. However, the need of better models demanded more complex and deep architecture as well. Kolbæk M, et al. introduced utterance-level permutation invariant training as a new norm for training speech separation model, the study used deep LSTM RNNs and bi-directional LSTM RNNs together with uPIT, and the output outperformed previous approaches and models [9].
While the previous models were designed for speech separation through mask estimation for each source in time-frequency representation, Luo Y, et al. directly modeled the signal in time domain using encode-decoder framework and significantly outperformed the state-of-the art causal systems which utilized time-frequency representation as input [10]. The extension of the dual-path BiLSTM, TasTas architecture obtained state-of-the-art performance when applied with iterative multi-stage refinement scheme (Figures 1-3) [11].

Figure 1: Perceiver architecture.

Figure 2: The masking-based source separation pipeline. Latent representation of the mixed signal is learned by the encode, the masking block estimates the masks for the source sound and decoder reconstructs the estimated sources.

Figure 3: Overall architecture of the masking network.
Introduction of the transformer model, revolutionized how data with long and short-term dependencies are approached, proposed a DPTNet for end-to-end monaural speech separation that employed improved transformer that enables direct context-aware modeling on speech sequences [12,13].
Subakan C, et al. introduced the model with state-of-the art performance, based on the transformer-model’s encoder part and unlike DPRNN’s RNN approach of the dual-path framework, this approach involved the use of a multi-scale pipeline that employs transformer to capture long and short-term dependencies [14]. The same team further studied the application of other transformer architectures like longformer, linformer and reformer, however, the result they obtained were nowhere near to their first approach [15].
With functionalities like speech recognition, synthesis or separation being more of commodities in daily lives than some far distant technologies, the advancement in the transformer-based speech separation models has promised a more economic path.
Perceiver
Perceiver is an efficient form of transformer architecture that has more enhanced performance than the original transformer.
This model (Figure 1) introduces the small set of latent units that form an attention bottleneck through which the inputs are required pass and the reduction is size of the Query (Q) hence eliminates the quadratic scaling problem associated with the original transformer [16]. The latent transformer presented in the paper resembles the decoder part of the original transformer. A transformer built on bytes has complexity O(LM2) while a latent transformer has complexity O(LN2) (where N << M), when considered as a function of the number of layers L in addition to index dimensionality. This results in an architecture with complexity O(MN+LN2).
Perciever-based speech separation transfotmer (perceparator)
This model closely resembles and relies on the masking-based source separation framework presented by (Figure 2) [14].
Encoder: The time-time domain mixture-signal x(t) ∈ RT, is fed into the encoder, it learns the time-frequency latent representation, e=ReLU(conv1d(x)).
Masking network: The masking network (Figure 3) is fed by the encoded representations e and estimates a mask mi for each of Ns speakers (Figures 4 and 5).

Figure 4: The perceparator block (Transformer based model).

Figure 5: Underlying architecture of perceiving and latent transformers.
The input e undergoes layer normalization, after which it is processed by a linear layer with F dimensions [17].
e=linearLayer(LayerNorm(e))
After normalization, the input is chunked into NC number of chunks of size C with optional overlapping factor of 50%. The output of the chunk can be represented as h′ ∈ RF × C × NC.
The chunked data is encoded with the positional embeddings, the sequential nature of the input data is evident of the necessity of the positional information for better performance. Moreover, the SOTA performance in the transformer-based speech separation model has proven its significance in their study [15].
The chunked data and a randomly initialized latent array of form, la ∈ RF × L × NC, are fed into the transformer-based-model block (i.e., Perceparator block) (Figure 4), which in fact employs the perceiver-like transformer model to deduce the inter-dependencies within the input data and learn to separate the sources. Its output can be represented as h′′=Perceparator (h′,la).
The output of the block has fewer dimensions than the input, so two linear layers are employed to get the original size of the data. The output can be represented as h′′′ ∈ RF × L × NC. Then a series of PReLU and a linear layer are employed to output according to the number of speakers, and output obtained has form h4 ∈ R(F × NS) C× NC.
The chunks are then combined, with overlapping to get the original length, h5 ∈ R(F × Ns) × T′ and finally passed through a feed forward network followed by ReLU layer to get the estimated masks.
mk=ReLU(FFW(h5)), k=1,…..,NS.
Decoder: Decoder of the model used the transposed convolutional layer with same stride and kernel size as the encoder. It receives the input from the element wise multiplication between the encoded input data and each mask generated for Ns sources.
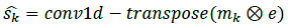
Experiments
Data: The experiment with the models has been done with the Libri2Mix dataset prepared form the LibriMix data available [18]. The mixture of two speakers is created by randomly mixing utterances in the LibriMix corpus. The training, cross-validation and testing data are prepared in the ratio 69:21:10.
Architecture setup: The encoder has 256 convolutional filters with a kernel size of 3, stride factor of 1 and padding 0. The decoder follows the same data.
In our best performing model, the chunk size is set to C=250, and overlapping is set to none. The latent array generation is done with random value initialization in the range (−2, 2), with mean 0, and standard deviation 0.02. The perceparator model block is repeated N=15 times, where within the block both perceiving and latent transformer has 16 parallel attention heads. The model has total 9.465 million parameters.
Training: The speech separation model uses AdamP as the optimization algorithm [19]. The learning rate is initialized to α=1e−4, forgetting factor for gradients β1=0.9, second moment of gradient β2=0.999 and weight decay wd=1e−2. The learning rate is halved at every x e poch where { ( x,y): x ∈ 25+n, y ∈ x, n ∈ {1,2,2,3,3,3,……}} (Table 1).
| SI-SNR (dB) | N | No. of perceiving transformer | No. of latent transformer | Learning rate | Overlapping | Params. (millions) |
|---|---|---|---|---|---|---|
| 10.89 | 20 | 1 | 6 | 1.5e-4 | 50% | 25.7 |
| 9.91 | 10 | 1 | 1 | 1e-4 | None | 6.729 |
| 12.85* | 15 | 1 | 1 | 1e-4 | None | 9.465 |
| Note: *Learning rate was halved with fixed interval | ||||||
Table 1: Perceparator with different hyperparameters.
The model uses SI-SNR via uPIT as an evaluation criterion. uPIT is a deep learning-based approach to speaker independent multi-speaker speech separation that is practical and can be applied end-to-end. This approach enhances the frame-level PIT method by integrating an utterance-level training criterion [20]. As a result, the need for speaker tracing or excessively large input/output contexts, which are necessary in the original PIT method, is eliminated.
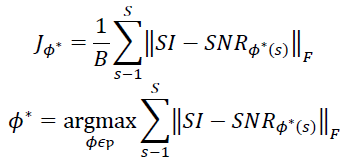
Training of the model was performed with the NVIDIA GTX 3060Ti with 8 GB of memory. Each epoch taking approximately 1.5 hours on the GPU, the model was trained for 450 epochs.
Libri2Mix dataset is the taken as the benchmark in this study. The model achieves the best result of SI-SNR improvement of 12.85 dB on the training course and with the test data, it achieved the performance of 10.5 dB SI-SNR on the test dataset. In Table 1, we study the effect of various hyper-parameters augmentation strategies. It is observed that the performance of the model saturates with the number of parameters being trained, the tweaking in the learning rate during the progression of training really affects the way model optimizes.
Table 2, shows the comparison between the different state-of-the art models and the model developed during this study. The result of the Perceparator lags behind the performance of the previous studies. The result suggests, the problem of speechseparation in the Perceparator model lies within the core, i.e., use of the latent-space for mask estimation (Figure 6).
| Model | SI-SNRi | Params. |
| Tasnet | 10.8 | - |
| Sepformer | 19.2 | 26 M |
| Perceparator** | 10.5 | 9.465 M |
| Note: *Pretrained model on different dataset, **Model developed in this study | ||
Table 2: Best results on Libri2Mix.

Figure 6: Training of the perceparator model (in epochs).
This study focuses on utilizing deep learning techniques, particularly using efficient form of the transformer architecture for speech separation.
Specifically, we built a speech separation model with the perceiver architecture, a transformer-based model eliminating quadratic complexity of the prior, and trained it to study the feasibility of efficient-transformers in speech separation and compared the it with other state of the art models.
Our result suggests that, efficient transformer models hold promising future for the speech separation tasks, enhancing performance with lower computational requirements, however, more study and researches in the field experimenting with other form of transformers lies ahead of us.
We convey our earnest thanks to the department of electronics and computer engineering, Thapathali campus for their invaluable support and opportunity to pursue study in this domain. The motivation, guidance, and resources we were provided there have been significant in the completion of this journey, we are grateful for their support throughout this study.
[Crossref] [Google Scholar] [PubMed]
Citation: Rijal S, Neupane R, Mainali SP, Regmi SK, Maharjan S (2025) Monaural Multi-Speaker Speech Separation Using Efficient Transformer Model. J Inform Tech Softw Eng. 15:426.
Received: 02-Aug-2023, Manuscript No. JITSE-23-25929; Editor assigned: 04-Aug-2023, Pre QC No. JITSE-23-25929 (PQ); Reviewed: 18-Aug-2023, QC No. JITSE-23-25929; Revised: 13-Jan-2025, Manuscript No. JITSE-23-25929 (R); Published: 20-Jan-2025 , DOI: 10.35248/2165-7866.25.15.426
Copyright: © 2025 Rijal S, et al. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.