Journal of Clinical and Experimental Cardiology
Open Access
ISSN: 2155-9880
ISSN: 2155-9880
Research Article - (2023)Volume 14, Issue 12
State public health agencies have collected massive mortality data at the county level over time. Those data sets are often stored in text-numeric formats, such as Comma-Separated Values (CSV).
Therefore, it is very difficult for the public and even health professionals to understand the spatial patterns of mortality across a state. On the other hand, health disparity has recently become a major topic in public health research, including health disparities in urban and rural areas, males and females, socioeconomic status, and race and ethnic groups. The objectives of this research are: 1) To determine if there are statistically significant spatial clusters of the mortality rates of heart disease at the county level in Illinois in 2020; and 2) To assess whether there is a significant difference the death rates between metropolitan counties and non-metropolitan counties. Spatial autocorrelation analysis (Global Moran’s I), cluster and outlier analysis (Local Moran’s I), and bivariate mapping method from ArcGIS Pro are performed to identify any significant spatial clusters/outliers of the mortality rates. Linear regression analysis between the mortality rates of heart disease in 2020 and the United States Center for Disease Control and Prevention’s Social Vulnerability Index (SVI) in 2020 is carried out to further analyze the spatial correlation between them. The results show that there exist spatial clusters/outliers of the mortality rates of heart disease across the state of Illinois; however, there is no statistically significant correlation between the mortality rates of heart disease and the SVI. By utilizing spatial and statistical analysis to explore the mortality rates of heart disease in metropolitan counties and non-metropolitan counties, this research aims to provide valuable insights for public health professionals and policymakers.
Spatial autocorrelation analysis; Cluster and outlier analysis; Spatial clusters/outliers; Mortality rates; Heart disease; Illinois
State public health agencies have collected massive public health data over time. Those data sets are often stored in numeric-text formats, such as Comma-Separated Values (CSV) or Portable Document Format (PDF). Therefore, it is very difficult for the public and even health professionals to understand the spatial and temporal patterns of the public health data across a state over time. Public health officials rely on data-driven information (intelligence) to make better decisions. From (big) data to information to intelligence to decision-making requires the use of “(spatial) data science” techniques, including spatial analysis and statistical analysis, visualization tools and geospatial technology. In the last two decades, medical Geographic Information System (GIS) has become a new research frontier in public health to help understand similarities and disparities of public health information across a specified geographic area [1-8]. Hu and Kolker document an interactive and animated cartographic approach to visualizing the spatiotemporal patterns of heart disease death rates from 2008 to 2020 in Illinois [9]. On the other hand, health disparity has recently become a major topic in public health research, including health disparities in race, economic groups, and ethnic groups, as well as health service disparities in urban and rural areas [10-12]. Khan, et al., conducted a study on the relationship between CDC’s Social Vulnerability Index (SVI) and premature cardiovascular mortality among US Counties from 2014 to 2018 [13]. They concluded that premature CVD mortality was higher in counties with more significant social vulnerabilities. Brown-Amilian and Akolade employed multiple spatial and statistical methods, including principal components analysis, linear regression, and Bivariate Local Indicators of Spatial Association (BiLISA) [14]. The results from the linear regression model and BiLISA clustering maps show there is a strong connection between COPD hospitalizations and socioeconomic status along with race.
The objectives of this research are: 1) To determine if there are statistically significant spatial clusters/outliers of the mortality rates of heart disease at the county level in Illinois in 2020; 2) To assess whether there is a significant difference in the death rates between metropolitan counties and non-metropolitan counties; and 3) To investigate if there is significant correlation between the mortality rates of heart disease and SVI. Spatial autocorrelation analysis (Global Moran’s I), cluster and outlier analysis (Local Moran’s I), and bivariate mapping technique, all from ArcGIS Pro, were performed. In addition, linear regression analysis between the mortality rates of heart disease in 2020 and SVI in 2020 was carried out.
Data sets
The main data sets for this study include 1) The base maps of the state boundary and the county boundary of Illinois, 2) The mortality data of heart disease in 2020 in Illinois, 3) The death statistics of all causes in 2020 in Illinois, and 4) The CDC’s SVI data in 2020 for Illinois. Each data set is described in more detail below.
Illinois state boundary and county boundary
The Illinois state boundary and Illinois county boundaries were extracted from the U.S. Census Bureau’s state boundary and county boundaries in ArcView shapefiles. The original spatial reference of the shapefiles was in the Geographic Coordinate System of North American Datum of 1983 (GCS_NAD_1983). The spatial reference of the shapefiles was then projected to NAD_1983_ StatePlane_Illinois_West_FIPS_1202_Feet. Both shapefiles serve as the base maps for creating Choropleth maps. The attribute table of the county boundary shapefile contains Name (for county name) as the attribute field. This field is used as the primary key to join the mortality data of heart disease in 2020, and the SVI data in 2020 for Illinois (see next two sections).
Mortality data of heart disease in 2020 in Illinois
Mortality data were downloaded from the Illinois Department of Public Health (IDPH) (www.data.illinois.gov/dataset/mortality- data-2008-to-2020). The data were stored in Comma-Separated Values (CSV) format, which can be imported into a Microsoft Excel spreadsheet. The spreadsheet has nine fields: Cause of death, county, sex, race or ethnicity, year, population estimate, death, crude death rate per 100,000 population, and age-adjusted death rate per 100,000 population [2]. The cause of death field lists the top ten causes of death, including heart disease, cancer, COVID-19, unintentional injuries, stroke, chronic lower respiratory diseases, Alzheimer’s disease, diabetes, kidney disease, and influenza or pneumonia. The county field includes Illinois and the name of each of the 102 counties in the state. The values for the sex field are All, M (male), and F (female). The race or ethnicity field has values of All, Hispanic (H), Non-Hispanic White (NHW), Non-Hispanic Black (NHB), and Non-Hispanic Other (NHO). The year field has values from 2008 through 2020.
There was a total of 220,936 rows in the Excel spreadsheet for the mortality data. Because the mortality rates of heart disease the focus of this study, the first step was to use the filter function in Excel to extract all the rows where the cause of death field has the value of disease of heart, which results in 20,085 rows. The second step was to extract values of sex=all. The third step was to extract values of race or ethnicity=all. The fourth step was to extract values of year=2020. The final step was to extract only the crude death rate per 100,000 population for all 102 counties. Up to this point, all the rows that represent the mortality data of heart disease for the year 2020 were extracted. The new Excel spreadsheet contains two fields: Name (for county name) and Rates (for mortality rates of heart disease in 2020) and was saved as CSV format, which will be used to join the attribute table of county boundary base map for spatial and statistical analysis and Choropleth mapping.
Social Vulnerability Index (SVI) data in 2020 for Illinois
The CDC/ATSDR SVI (Centers for Disease Control and Prevention/Agency for Toxic Substances and Disease Registry Social Vulnerability Index) takes into account various factors that contribute to a community's vulnerability, including socioeconomic status, race and ethnicity, housing, transportation, and other demographic and economic factors, as follows.
SVI-Theme 1: Socioeconomic status (below 150% poverty, unemployed, housing cost burden, no high school diploma, no health insurance).
SVI-Theme 2: Household characteristics (aged 65 or older, aged 17 or younger, civilian with a disability, single-parent households, English language proficiency).
SVI-Theme 3: Racial and ethnic minority status (Hispanic or Latino (of any race); Black and African American, Not Hispanic or Latino, American Indian and Alaska Native, Not Hispanic or Latino, Asian, Not Hispanic or Latino, Native Hawaiian and Other Pacific Islander, Not Hispanic or Latino, Two or More Races, Not Hispanic or Latino, Other Races, Not Hispanic or Latino).
SVI-Theme 4: Housing type and transportation (multi-unit structures, mobile homes, crowding, no vehicle, group quarters).
The scores for SVI as well as each of the SVI themes (i.e. SVI- Themes 1 through 4) range from 0 (lowest vulnerability) to 1 (highest vulnerability). For instance, SVI score of 0.75 indicates a medium to high level of vulnerability.
The SVI data, including all four themes, are available at the census tract and county level for 2020 for all the counties in Illinois. They were downloaded in CSV format from CDC/ATSDR’s website (www.atsdr.cdc.gov/placeandhealth/svi/data_documentation_ download.html). The SVI data were later joined with the attribute table of the Illinois county base map for simple linear regression analysis and Choropleth mapping.
Simple statistical analysis and spatial distribution of the mortality data of heart disease across the state
A simple statistical analysis was conducted in ArcGIS Pro to obtain the basic statistics, including the minimum, maximum, mean, mode, median, standard deviation, skewness and kurtosis, of the mortality data of heart disease in 2020 for all 102 counties [5]. A thematic map displaying the counties below or above the median was made in ArcGIS Pro to visualize the spatial distribution of the mortality rates across the state. Further, this map can be compared with another map showing the locations of metropolitan counties and non-metropolitan counties.
Spatial autocorrelation analysis
Spatial autocorrelation analysis (Global Moran’s I), briefly SAA thereafter, in ArcGIS Pro was performed to help answer the question of whether there are statistically significant spatial clusters/outliers of the mortality rates of heart disease across the state. The SAA tool will generate three important spatial statistics: The Global Moran's I, the Z-score, and the p-value. The Global Moran's I provides a single measure to assess the spatial autocorrelation of a variable for the entire dataset. That means the Global Moran’s I helps determine if there is a pattern of similarity (cluster) or dissimilarity (outlier) in the values of a variable across the entire geographic space. The Global Moran's I range from -1 to 1. A positive value indicates positive spatial autocorrelation (similar values cluster together), a negative value indicates negative spatial autocorrelation (dissimilar values cluster together), and a value near zero suggests no spatial autocorrelation or random. The Z-score is a measure of how many standard deviations the observed Moran's I value is from the mean Moran's I value expected under spatial randomness. A higher Z-score indicates a stronger departure from spatial randomness. The p-value is associated with the Z-score and is used to assess the statistical significance of the Moran's I value. A p-value of less than 0.05 (or p ≤ 0.05) suggests that the observed Moran's I value is highly statistically significant, indicating a strong spatial autocorrelation or spatial cluster.
Clusters and outlier analysis
The clusters and outlier analysis (Anselin Local Moran’s I), briefly COA thereafter, in ArcGIS Pro can be used to identify where the statistically significant spatial clusters (i.e. the concentrations of high values or concentrations of low values) and spatial outliers (a high value surrounded by low values or a low value surrounded by high values) are located across the study area (Anselin 1995) [15]. Given the input feature class, such as the Illinois county boundary layer and input field, such as the mortality rates of heart disease, the COA tool calculates a local Moran's I value, a z-score, a pseudo p-value, and a code (COType) representing the cluster type for each statistically significant feature (i.e., county). In addition, the COA tool creates a new Output Feature Class with the following attributes for each feature (e.g. county) in the Input Feature Class: Local Moran's I index, z-score, pseudo p-value, and cluster/outlier type (COType). A positive local Moran’s I value indicates that a feature has neighboring features with similarly high or low attribute values; this feature is part of a cluster. A negative local Moran’s I value indicates that a feature has neighboring features with dissimilar values; this feature is an outlier. The z-scores and pseudo p-values represent the statistical significance of the computed index values. In either case, the p-value for the feature must be small enough (i.e. p ≤ 0.05) for the cluster or outlier to be considered statistically significant. The COType field distinguishes between a statistically significant spatial cluster of High value to High value (HH), spatial cluster of Low value to Low value (LL), spatial outlier in which a High value is surrounded primarily by Low values (HL), and spatial outlier in which a Low value is surrounded primarily by High values (LH). Statistical significance is set at the 95 percent confidence level.
Bivariate choropleth mapping
Bivariate map, often called bivariate choropleth map, is a special mapping technique that could show the quantitative relationship between two themes or variables [16]. This type of map uses symbology of bivariate color schemes to visually compare values with each color scheme representing one theme or variable. ArcGIS Pro allows us to use two attribute fields representing the two variables to generate a bivariate map with 3 x 3, or 4 x 4 grid size. A 3 x 3 grid size creates a square grid of nine unique colors with light color to represent low value for each variable and dark color to represent high value for each variable.
Linear regression analysis
A linear regression analysis in IMB SPSS (Version 29.0.1.0) between the mortality rates of heart disease (dependent variable) and SVI (independent variable, or predictor) was performed to check if there is spatial correlation between two variables. The linear regression analysis will report the R value, R2, F-Statistic, and Significance level, so a strong, weak or no correlation between the two variables can be determined.
The next a few sections will present the results of the multiple analyses, as follows.
Results from the simple statistical analysis of the mortality rates of heart disease
At first glance, the mortality rates of heart disease were examined to derive simple statistics, such as minimum rate of 112.52, maximum rate of 420.17, mean of 288.31, mode value of 289.635, median value of 289.635, stand deviation of 70.66, skewness of -0.11 and Kurtosis of 2.36. The skewness is a measure of symmetry or asymmetry of data distribution, so, -0.11 skewness value indicates that the data distribution is mostly symmetrical. Kurtosis, on the other hand, measures whether the data set is heavy-tailed (high peak) or short-tailed (low peak) in a distribution. Data set with normal distribution has a Kurtosis value of 3. High Kurtosis (>3) have heavy tails and more outliers, while data sets with low kurtosis (<3) tend to have light tails and fewer outliers. So, the mortality rates of heart disease with a Kurtosis value of 2.36 seem to have light tails and fewer outliers.
Two Choropleth maps were created, one to show where the metropolitan counties and non-metropolitan counties are located in the state, and the other to show where the counties above or below the median value of the mortality rate of heart disease (Figure 1).

Figure 1: (a) Metropolitan counties and non-metropolitan counties; (b) Counties with below or above the median value of the mortality rates of heart disease in 2020. Note: (a)  : Metropolitan country;
: Metropolitan country;  :Non-metropolitan country; (b)
:Non-metropolitan country; (b)  : Below the median;
: Below the median; 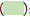 : Above the median
: Above the median
Among all the 28 metropolitan counties, 23 counties are below the median value (Table 1). That means, 82 percent of the metropolitan counties are below the median value. On the other hand, among all the 74 non-metropolitan counties, 46 counties are above the median value. That means, 64 percent or approximately 2/3 of the non-metropolitan counties are above the median value.
| # (%) of Metropolitan county | # (%) of Non-metropolitan county | Subtotal | |
|---|---|---|---|
| Above median | 5 (18%) | 46 (64%) | 51 |
| Below median | 23 (82%) | 28 (36%) | 51 |
| Subtotal | 28 (100%) | 74 (100%) | 102 |
Table 1: The number and percentage of the counties that are blow or above the median value.
Results from the SAA on the mortality rates of heart disease
As mentioned in the methodology section, SAA reports three spatial statistics: Global Moran’s I, Z-score and p-value. Reported in Table 2 are the spatial statistics from the SAA. All the Global Moran’s I are positive but low values; all the Z-scores are greater than 4.0 with p ≤ 0.00. These spatial statistics all indicate that there exist statistically significant spatial clusters in the data set. Notice also in Table 2 are different conceptualization of the spatial relationships: Inverse distance, contiguity edge only, and contiguity edges corners. The idea behind the Inverse Distance is simply based on Waldo Tobler’s First Law of Geography, which states that "everything is related to everything else, but near things are more related than distant things" (Tobler, 1970). In other words, for Inverse Distance spatial relationships, all features impact or influence all other features, but the farther away, the smaller the impact it has. For contiguity edges only, features that share an edge (that have coincident boundaries) are included in computations for the target feature [17]. For contiguity edges corners, features that share an edge or a corner will be included in computations for the target feature. However, the Global Moran’s I will not inform where the spatial clusters are in the study area. That is the reason why the COA is necessary for this research, which could inform where the spatial clusters are located.
| Conceptualization of spatial relationships | Global Moran's I | Z-score | p-value | Distance threshold (feet) |
|---|---|---|---|---|
| Inverse distance | 0.069478 | 4.167827 | 0 | 654133.9342 |
| Inverse distance | 0.353574 | 4.482226 | 0 | 141291.7012 |
| Contiguity edges only | 0.237276 | 4.087121 | 0 | - |
| Contiguity edges corners | 0.255267 | 4.472608 | 0 | - |
Table 2: Spatial statistics from the SAA.
Results from the COA
The COA tool calculates a local Moran's I value, a z-score, a pseudo p-value, and a code (COType) representing the cluster type for each statistically significant feature (i.e. county). Figure 2 shows statistically significant spatial clusters/outliers of the mortality rates of heart disease across the state. Table 3 reports the spatial statistics from the COA.

Figure 2: Statistically significant spatial clusters/outliers for the
mortality rates of heart disease. Feature IDs on the map correspond
to the Feature IDs (Table 3). Note: ( ) High-high cluster;
) High-high cluster;  High-low outlier;
High-low outlier;  Low-high outlier;
Low-high outlier;  Low-low cluster;
Low-low cluster;
 Not significant.
Not significant.
| Feature ID | Local Moran's I | Z-score | p-value | COType |
|---|---|---|---|---|
| 3 | 6.638202 | 2.25 | 0.018 | LL |
| 15 | 9.269612 | 4.06 | 0.002 | LL |
| 18 | 13.51028 | 3.02 | 0.002 | LL |
| 21 | 12.51734 | 3.72 | 0.002 | LL |
| 44 | 20.21727 | 4.75 | 0.002 | LL |
| 46 | 19.44785 | 3.5 | 0.002 | LL |
| 48 | 4.811075 | 1.88 | 0.034 | LL |
| 54 | 0.863969 | 2.3 | 0.008 | HH |
| 55 | 12.75706 | 3.89 | 0.002 | LL |
| 65 | -4.97806 | -2.62 | 0.004 | LH |
| 78 | 0.689674 | 1.57 | 0.05 | LL |
| 95 | -0.95767 | -1.89 | 0.026 | LH |
| 98 | 12.3195 | 3.15 | 0.002 | LL |
| 100 | 1.465347 | 1.87 | 0.038 | LL |
Note: Low-to-Low (LL); High-to-High (HH); Low-to-High (LH)
Table 3: Spatial statistics from COA.
The Northeast portion of the state is the City of Chicago. All the neighboring counties are metropolitan counties, and they have low mortality rate of heart disease, forming a Low-to-Low (LL) cluster.
McDonough County feature ID 54 (Table 3) has a Local Moran’s I of 0.863969, a z-score of 2.3, a p-value of 0.008 (p ≤ 0.05), and COType value of HH, which indicates McDonough County is a statistically significant spatial cluster of high values (high value surrounded by high values). Upon checking the heart disease death rates, McDonough County has a rate of 300, surrounded by 373 (Hancock County), 397.86 (Henderson County), 419.26 (Warren County) and 341.35 (Fulton County); Randolph County feature ID 78 (Table 3) has a Local Moran’s I of 0.689674, a z-score of 1.57, a p-value of 0.05 (p ≤ 0.05), and COType value of LL, which indicates Randolph County is a statistically significant spatial cluster of low values (low value surrounded by low values). Upon checking the heart disease death rates, Randolph County has a rate of 274.31, surrounded by 218.77 (Monroe County), 224.38 (St. Clair County), 254.29 (Washington County), 256.48 (Perry County) and 241.73 (Jackson County); Wayne County feature ID 95 (Table 3) has a Local Moran’s I of -0.95767, a z-score of -1.89, a p-value of 0.026 (p ≤ 0.05), and COType value of LH, which indicates Wayne County is a statistically significant spatial outlier of low value surrounded by high values. Upon checking the heart disease death rates, Wayne County has a rate of 274.47, surrounded by 350.92 (Marion County), 389.94 (Clay County), 348.23 (Richland County), 393.33 (Edwards County), 316.91 (White County), and 329.24 (Jefferson County).
Bivariate map of the mortality rates of heart disease and SVI
Figure 3 uses the bivariate color scheme to demonstrate the spatial associations between the mortality rates of heart disease and the SVI with three discrete classes each based on the natural breaks (Jenks) data classification method. The three classes in the mortality rates variable are: Less than or equal to 242.8 (low death rate); greater than 242.8 but less than or equal to 327.45 (medium death rate); greater than 327.45 (high death rate). The three classes in the SVI variable are: Less than or equal to 0.3267 (low social venerability); greater than 0.3267 but less than or equal to 0.6634 (medium social vulnerability); greater than 0.6634 (high social venerability). The data classification method used for both variables is natural break (Jenks), which investigates the largest differences within the values in each variable [18].

Figure 3: Bivariate map of the mortality rates of heart disease and
SVI. Note:  High;
High; 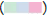 Low;
Low; 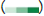 Death rate;
Death rate; 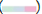 SVI.
SVI.
A simple query (e.g. select by attributes) in ArcGIS Pro could provide the list of counties with the mortality rate greater than 327.45 (high death rate) and the SVI greater than 0.6634 (high social venerability) (Table 5). Among all eight counties with High-to- High association, only Kankakee County is a metropolitan county and the other seven are non-metropolitan counties, indicating the majority or 87.5 percent of the High-to-High counties are non- metropolitan counties.
Similarly, a simple query in ArcGIS Pro could provide the list of counties with the mortality rate less than or equal to 242.8 (low death rate) and the SVI less than or equal to 0.3267 (low social venerability) (Table 4). Among all nine counties with Low-to- Low association, only Effingham County and Mercer County are non-metropolitan counties and the other seven are metropolitan counties, indicating the majority or 78 percent of the Low-to-Low counties are metropolitan counties.
| County name | Mortality rate | SVI | Metropolitan county (Y/N) |
|---|---|---|---|
| xDuPage | 164.91 | 0.3267 | Yes |
| Effingham | 187.88 | 0.3168 | No |
| Grundy | 215.72 | 0.198 | Yes |
| Kendall | 112.52 | 0.2277 | Yes |
| McHenry | 176.54 | 0.2871 | Yes |
| Menard | 215.45 | 0.0198 | Yes |
| Mercer | 223.32 | 0.1287 | No |
| Monroe | 218.77 | 0 | Yes |
| St. Clair | 224.38 | 0.1188 | Yes |
Table 4: List of the counties with low values of the mortality rate and low values of SVI.
Results from the linear regression analysis
A simple linear regression analysis was carried out in SPSS between the dependent variable (heart disease death rates or Stroke death rates) and the independent variable or predicator (SVI or SVI Themes). The purpose of doing this analysis was to see if there is any correlation between the mortality rates of heart disease and the CDC’s SVI values (see Section 2.4 Data Sets). The results are reported in Table 6 below.
| County name | Mortality rate | SVI | Metropolitan county (Y/N) |
|---|---|---|---|
| Warren | 419.26 | 0.7624 | No |
| Knox | 350.64 | 0.901 | No |
| Morgan | 335.33 | 0.7723 | No |
| Kankakee | 340.72 | 0.9406 | Yes |
| Marion | 350.92 | 0.7822 | No |
| Clay | 389.94 | 0.6733 | No |
| Union | 387.93 | 0.8416 | No |
| Pulaski | 346.09 | 0.7129 | No |
Table 5: List of the counties with high values of the mortality rate and high values of SVI.
The R values in Table 6 represent the simple correlation between the dependent variable (the mortality rates of heart disease) and the predicator (SVI or SVI Themes). Overall, the R values are low, which indicate very low degree of correlation. The R2 value indicates how much of the total variation in the dependent variable can be explained by the independent variable. In the case of 0.007, only 0.7% can be explained, which is very low. This table also indicates that the regression model predicts the dependent variable poorly. The "Sig." column indicates the statistical significance of the regression model. All Sig. are greater than 0.05, indicating that, overall, the regression model could not statistically significantly predict the outcome variable (i.e. it is a very poor fit for the data).
| Dependent variable | Independent variable | R | R2 | F | Sig. |
|---|---|---|---|---|---|
| Mortality rates of heart disease | SVI | 0.082 | 0.007 | 0.676 | 0.413 |
| SVI-Theme 1 | 0.078 | 0.006 | 0.607 | 0.438 | |
| SVI-Theme 2 | 0.126 | 0.016 | 1.608 | 0.208 | |
| SVI-Theme 3 | 0.065 | 0.004 | 0.427 | 0.515 | |
| SVI-Theme 4 | 0.004 | 0 | 0.002 | 0.965 |
Table 6: Model summary from the linear regression analysis.
This research began with a simple spatial and statistical analysis on the mortality rates of heart disease in 2020 in Illinois by looking at the minimum, maximum, mean, mode, median, skewness and Kurtosis and by mapping the counties with below or above the median value of the mortality rates of heart disease. From this step, this study found that 82 percent of the counties that are below the median rate are metropolitan counties. However, 64 percent of the counties that were above the median rate are non-metropolitan counties. Then, through the SAA and COA, it was found that, overall, there existed statistically significant clusters of high values and low values of the mortality rates of heart disease across the state. The statistically significant spatial cluster of high values were all located in non-metropolitan counties, but the statistically significant spatial cluster of low values were all located in metropolitan counties, indicating further there did exist disparities between metropolitan counties and non-metropolitan counties in the spatial distribution of the mortality rates of heart disease in the state. In addition, the bivariate map demonstrated that 87.5 percent of the high-to-high counties were non-metropolitan counties and 78 percent of the low-to-low counties were metropolitan counties. The linear regression analysis revealed that there was a very low degree of correlation between the mortality rates of heart disease and the CDC’s SVI scores in 2020 in Illinois.
It was unfortunate that the mortality rates of heart disease in 2020 in Illinois contained missing values for some counties in males and females, and race/ethnicity groups, resulting in its inability to perform the research on the disparity of the mortality rates of heart disease in those groups in 2020 in Illinois. However, the research methodology presented in this paper can be applied in many public health studies if the data is available.
The Graduate School of SIUE will support 75% of the total cost for publication.
[Crossref] [Google Scholar] [PubMed]
[Crossref] [Google Scholar] [PubMed]
[Crossref] [Google Scholar] [PubMed]
[Crossref] [Google Scholar] [PubMed]
[Crossref] [Google Scholar] [PubMed]
[Crossref] [Google Scholar] [PubMed]
[Crossref] [Google Scholar] [PubMed]
[Crossref] [Google Scholar] [PubMed]
[Crossref] [Google Scholar] [PubMed]
[Crossref] [Google Scholar] [PubMed]
[Crossref] [Google Scholar] [PubMed]
Citation: Hu S (2023) Spatial and Statistical Analyses of the Mortality Rates of Heart Disease in 2020 in Illinois, USA. J Clin Exp Cardiolog.14:853.
Received: 01-Nov-2023, Manuscript No. JCEC-23-27865; Editor assigned: 03-Nov-2023, Pre QC No. JCEC-23-27865 (PQ); Reviewed: 17-Nov-2023, QC No. JCEC-23-27865; Revised: 24-Nov-2023, Manuscript No. JCEC-23-27865 (R); Published: 01-Dec-2023 , DOI: 10.35248/2155-9880.23.14.853
Copyright: © 2023 Hu S. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.